




最近米国株に関するニュースを紹介する動画をYoutubeに投稿するようになりました。
普段はSmartNewsで出てくるニュースをたらたらと読み、その中で面白いニュースを動画にしています。しかしそれだけでなく、もっと情報収集をしたいと考えていて、ただ普通に情報収集するのではなくなるべく簡単にできないかと考えて、今回紹介するWEBアプリを作成しました。
まだまだ改良したい点はありますが、この形は違う用途にも使い回ししやすいと思いますので紹介します!
この記事のゴール
以下が成果物です。Bloombergからトップニュースのタイトル及びURLを取得して、それぞれの記事を要約して、HTMLで表示するというものです。

手順
Youtubeでも紹介していますので、合わせて見るとわかりやすいかもしれません。
必要なライブラリをインストールする
ローカル環境だけでなく、サーバー側にもインストールしておきましょう。
pip install tinysegmenter
pip install sumy
pip install requests
pip install beautifulsoup4まず1つ目のtinysegmenterは日本語に対応させるためのライブラリです。
2つ目のsumyが記事を要約してくれるライブラリです。
3つ目、4つ目はスクレイピングのためのライブラリです。
トップニュースを取得するコードを書く
まずはトップニュースをスクレイピングにて取得する設定をします。
import requests
from bs4 import BeautifulSoup
import re
# トップページ情報を取得する
URL = "https://www.bloomberg.co.jp/"
rest = requests.get(URL)
# BeautifulSoupにニュースのページ内容を読み込ませる
soup = BeautifulSoup(rest.text, "html.parser")
# ニュースの見出しとURLの情報を取得して出力する
data_list = soup.find_all('article', class_='hero-module__story mod-story')
for data in data_list:
article = data.find('a', class_='hero-module__headline-link')
print(article.string.lstrip())
link = "https://www.bloomberg.co.jp/" + article.get('href')
print(link)スクレイピングしたいサイト、今回はBloombergにアクセスし、トップニュースの1つにカーソルを合わせて右クリックして「検証」をクリックします。
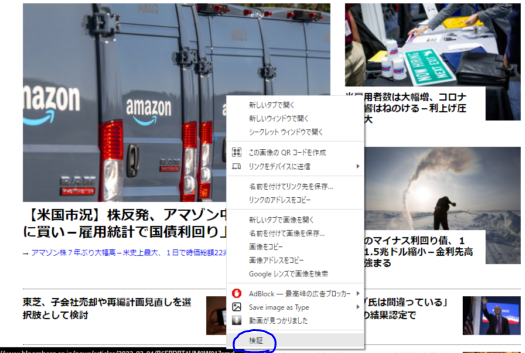
すると以下のようにHTMLが出てきます。

コードを見ると、トップニュースの1つずつが<article class=”hero-module__story mod-story” ・・・に入っていることがわかります。それが上部に3つ、下部に3つある構造のようです。
そのため、以下のようにそのarticleタグをfind_allで6つ取得します。
data_list = soup.find_all('article', class_='hero-module__story mod-story')続いて、上記タグを細かく見ていくと、<a href=”・・・・・” class=’hero-module__headline-link’・・・・というタグがタイトルを表していることがわかります。タイトルにカーソルを当てて検証画面見るほうが早いですが。しかも、タイトルだけでなく記事のリンクも同じタグなのでラッキーパターンです。
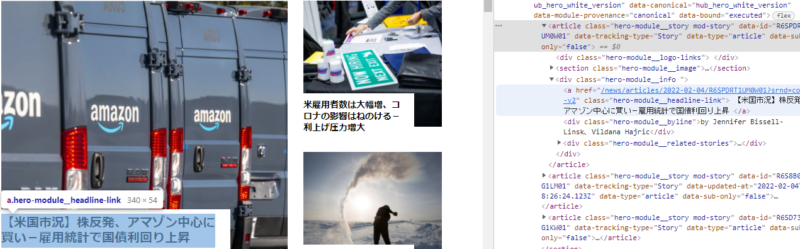
そのため、以下3行目のように、先ほど取得した6つのトップニュースが入っているdata_listをfor文で1つずつ取り出し(上の記事から順に)上記<a>タグを取得してarticleに入れます。
4行目のarticle.string.lstrip()の意味はテキストだけにして(string)、最初の空欄を消す(lstrip())という意味です。
article.get(‘href’)で記事のリンクが取得できますが、https://www.bloomberg.co.jp/XXXXXXのXXXXXX部分しか取得できないので、5行目のようにhttps://www.bloomberg.co.jp/を頭につけています。
data_list = soup.find_all('article', class_='hero-module__story mod-story')
for data in data_list:
article = data.find('a', class_='hero-module__headline-link')
print(article.string.lstrip())
link = "https://www.bloomberg.co.jp/" + article.get('href')
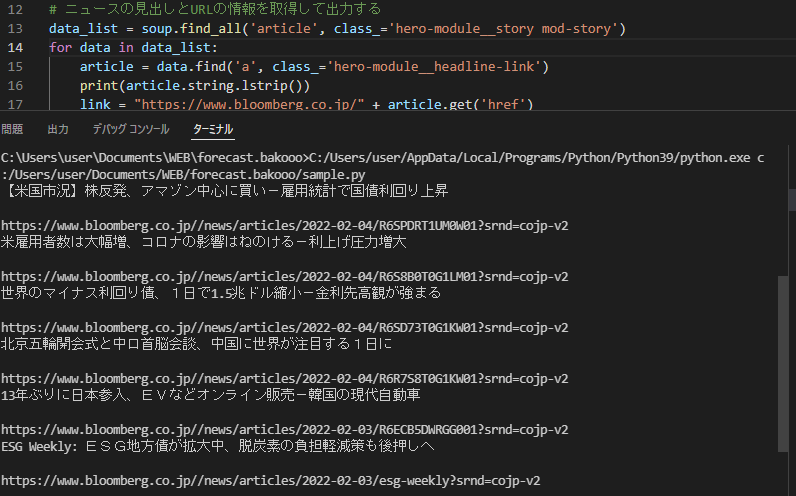
print(link)以上のコードで実行するとトップニュースのタイトルと記事のリンクがコンソールに表示されると思います。
sumyライブラリで要約するコードを作成する
一旦別ファイルで動作を確認しましたが、以下のようにコードを記載したら記事を要約してくれます。少々長いですが、おまじないだと割り切りましょう(笑)
from __future__ import absolute_import
from __future__ import division, print_function, unicode_literals
from sumy.parsers.html import HtmlParser
from sumy.nlp.tokenizers import Tokenizer
from sumy.summarizers.lex_rank import LexRankSummarizer as Summarizer
from sumy.nlp.stemmers import Stemmer
from sumy.utils import get_stop_words
LANGUAGE = "japanese"
SENTENCES_COUNT = 3
url = "https://www.bloomberg.co.jp/news/articles/2022-02-04/R6SPDRT1UM0W01?srnd=cojp-v2"
parser = HtmlParser.from_url(url, Tokenizer(LANGUAGE))
stemmer = Stemmer(LANGUAGE)
summarizer = Summarizer(stemmer)
summarizer.stop_words = get_stop_words(LANGUAGE)
for sentence in summarizer(parser.document, SENTENCES_COUNT):
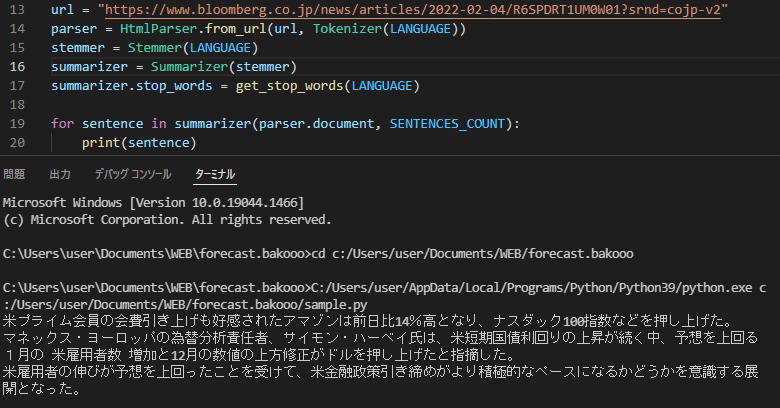
print(sentence)ポイントは「言語の設定、何文に要約するか(上記では3文)、それからどのURLの記事を要約するか」です。
実行すると以下のように要約された文が3つ表示されます。
WEBで表示できるよう設定する
先日紹介したこの記事の内容を使います。

#!/opt/alt/python36/bin/python3.6
# -*- coding: utf-8 -*-
from __future__ import absolute_import
from __future__ import division, print_function, unicode_literals
import cgi
import sys
import io
sys.stdout = io.TextIOWrapper(sys.stdout.buffer, encoding='utf-8')
from sumy.parsers.html import HtmlParser
from sumy.nlp.tokenizers import Tokenizer
from sumy.summarizers.lex_rank import LexRankSummarizer as Summarizer
from sumy.nlp.stemmers import Stemmer
from sumy.utils import get_stop_words
LANGUAGE = "japanese"
SENTENCES_COUNT = 3
url = "https://www.bloomberg.co.jp/news/articles/2022-02-04/R6SPDRT1UM0W01?srnd=cojp-v2"
parser = HtmlParser.from_url(url, Tokenizer(LANGUAGE))
stemmer = Stemmer(LANGUAGE)
summarizer = Summarizer(stemmer)
summarizer.stop_words = get_stop_words(LANGUAGE)
#文字表示
print('Content-Type: text/html; charset=UTF-8\n')
html_body = """
<!DOCTYPE html>
<html>
<head><title>Bakooo</title>
</haed>
<body>
<h1>Today's news</h1>
</body>
</html>
"""
print(html_body)
for sentence in summarizer(parser.document, SENTENCES_COUNT):
print(sentence)先ほどの要約設定を試したファイルにいくつかおまじないを追加しています。
1行目はレンタルサーバーの環境によって異なりますが、SSH接続してwhich pythonのコマンドで確認できます。
自分はConoha Wingを使用しています。
25行目から36行目もおまじないですが、きれいに表示させたい場合はこの中に要約した結果を入れ込みます。一旦はこのままで、その下に要約の結果をprintで表示させます。
そして、ファイル名を○○.cgiにしてファイルサーバーのドメイン以下で好みの場所に保存して、実行できるようにパーミッションを755にします。
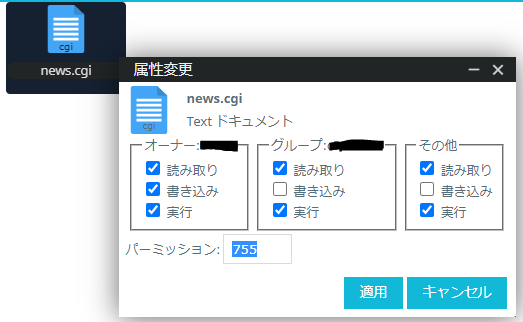
そしてアクセスして表示されるかを確認します。自分はドメイン以下にnewsというフォルダを作り、その中に保存したので、https://ドメイン/news/news.cgiにアクセスしました。以下のように表示できました。
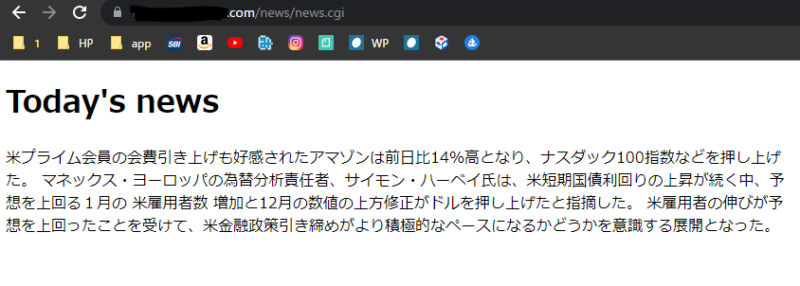
これでほぼ設定は完了です。
仕上げ
あとは、スクレイピングのfor文の中にsumyの文を入れてあげたらスクレイピングからの要約というプログラミングが実現します。
きれいな文ではないですが、参考にどうぞ。
#!/opt/alt/python36/bin/python3.6
# -*- coding: utf-8 -*-
from __future__ import absolute_import
from __future__ import division, print_function, unicode_literals
import cgi
from os import link
import sys
import io
sys.stdout = io.TextIOWrapper(sys.stdout.buffer, encoding='utf-8')
from sumy.parsers.html import HtmlParser
from sumy.nlp.tokenizers import Tokenizer
from sumy.summarizers.lex_rank import LexRankSummarizer as Summarizer
from sumy.nlp.stemmers import Stemmer
from sumy.utils import get_stop_words
import requests
from bs4 import BeautifulSoup
import re
LANGUAGE = "japanese"
SENTENCES_COUNT = 3
#文字表示
print('Content-Type: text/html; charset=UTF-8\n')
html_body = """
<!DOCTYPE html>
<html>
<head><title>Bakooo-News</title>
</haed>
<body>
<h1>Today's news from Bloomberg</h1>
"""
print(html_body)
# トップページ情報を取得する
URL = "https://www.bloomberg.co.jp/"
rest = requests.get(URL)
# BeautifulSoupにニュースのページ内容を読み込ませる
soup = BeautifulSoup(rest.text, "html.parser")
# ニュースの見出しとURLの情報を取得して出力する
data_list = soup.find_all('article', class_='hero-module__story mod-story')
for data in data_list:
article = data.find('a', class_='hero-module__headline-link')
print('<h2 style="background:#c2edff;">')
print(article.string.lstrip())
print('</h2>')
link = "https://www.bloomberg.co.jp/" + article.get('href')
print('<a href='+link + '>')
print(link)
print('</a>')
print('<h3>')
print('要約')
print('</h3>')
parser = HtmlParser.from_url(link, Tokenizer(LANGUAGE))
stemmer = Stemmer(LANGUAGE)
summarizer = Summarizer(stemmer)
summarizer.stop_words = get_stop_words(LANGUAGE)
print('<ul>')
for sentence in summarizer(parser.document, SENTENCES_COUNT):
print('<li>')
print(sentence)
print('</li>')
print('</ul>')
html_after = '</body></html>'
print(html_after)以上のコードでこのように表示させることができます。

少々難しいですが、他にも汎用できる形がつくれると思います。


コメント