




WEBサイトの情報を収集するスクレイピング、PythonやJavascriptで行うためプログラミングのスキルが必要で諦めている方もいらっしゃるのではないでしょうか。
もちろん、必要な情報によってはプログラミングでないとうまく収集できないものもありますが、だいぶ様々な情報がGoogle Spreadsheetのシンプルな関数だけで自動で収集できるようになります。
それはIMPORTXMLという関数です。しかもコピペを2回するだけで関数設定ができちゃいます。
手順
動画でも紹介しています!
まずはGoogle スプレッドシートを開きます。

そして関数を入力します
=IMPORTXMLと入力をします。カッコ内には(URL,XPath)が入ります。
それぞれを入力するときには””で囲みます。以下のようなイメージです。
=IMPORTXML(“https://XXXXXXXX.com/”,”//*[@id=’content’]/div/span”)
注意点は後ほど触れます。まず流れを説明します。
収集したい情報があるWEBサイトのURLをコピペする
今回はこちらの株価を取得したいと思いますので、「https://www.bloomberg.co.jp/markets/stocks/world-indexes/americas」をコピペします。
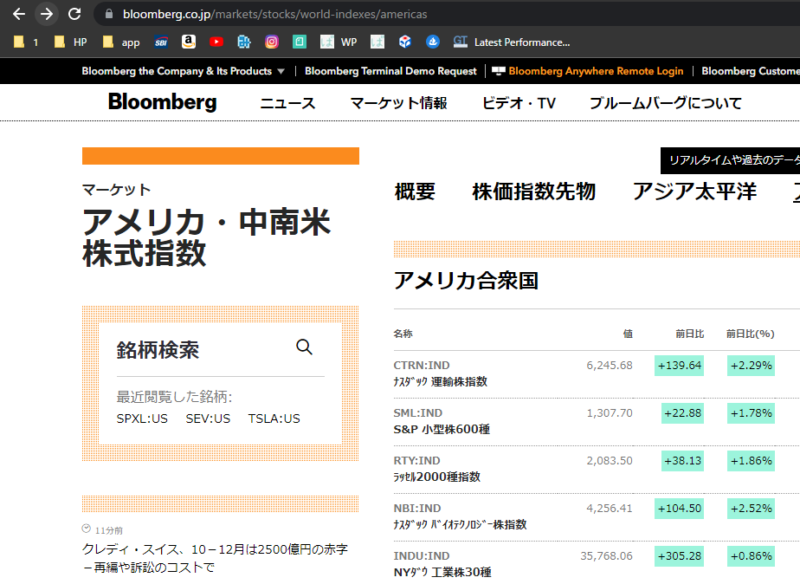
以下の感じです。
=IMPORTXML(“https://www.bloomberg.co.jp/markets/stocks/world-indexes/americas“,
次にXPathをコピペします
XPathとは簡単に言ったら住所みたいなものです。コピペするだけなので細かいことは気にしなくて大丈夫です。
詳しく知りたい方は以下の記事などを参考にしてください。

以下の数字を取得したいので数字の上で右クリックします。
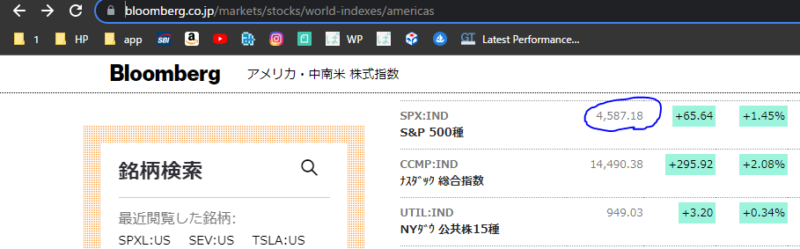
するとこのような画面に切り替わります。そして一部色が塗られた状態になっているかと思います。
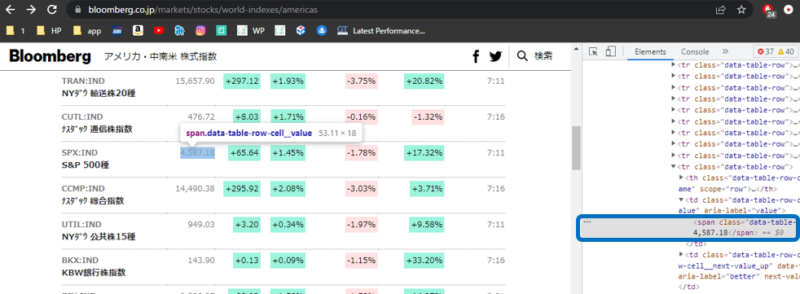
その色が塗られた箇所で右クリック>>Copy>>CopyXPathをクリックします。これでXPathがコピーされました。
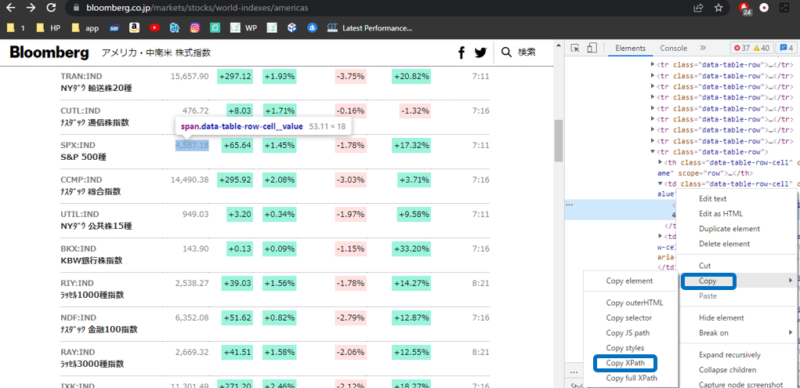
あとは先ほどの関数に入力してあげるだけです。
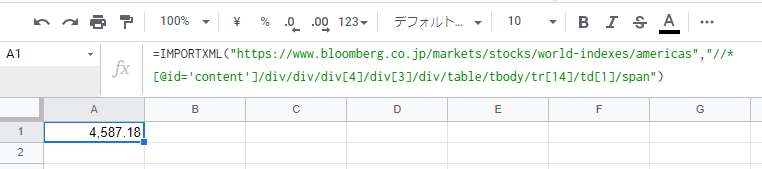
=IMPORTXML(“https://www.bloomberg.co.jp/markets/stocks/world-indexes/americas”,”//*[@id=”content”]/div/div/div[4]/div[3]/div/table/tbody/tr[14]/td[1]/span“)
ただ、ここで注意点があります!
「”」ダブルクォーテーションでXPathを囲むのですが、もしXPath内に「”」ダブルクォーテーションで囲まれた部分があったら「’」シングルクォーテーションに変えてあげる必要があります。
=IMPORTXML(“https://www.bloomberg.co.jp/markets/stocks/world-indexes/americas”,”//*[@id=‘content‘]/div/div/div[4]/div[3]/div/table/tbody/tr[14]/td[1]/span”)
完成!
このように情報が取得できたかと思います。
注意点
・EXCELでは使用できず、Google スプレッドシートのみで使用可能な関数です。
・この関数は2時間ごとの更新であること
場合によってはもっと簡単な方法も可能
さきほどは、IMPORTXMLでしたが、IMPORTHTMLという関数を使うと表全体を以下の数式だけで取得できちゃいます。
=IMPORTHTML(“https://www.bloomberg.co.jp/markets/stocks/world-indexes/americas”,”table”,”1″)
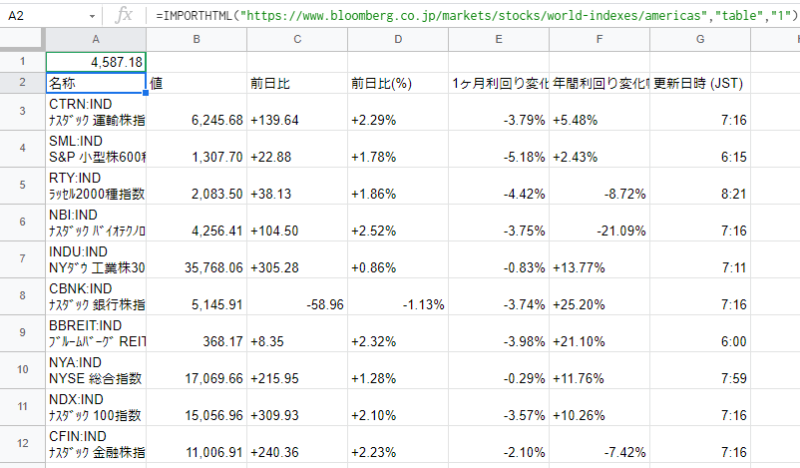
数式はIMPORTHTML(“URL”, “形式”,”何個目か”)
形式はtableかlistを選択可能です。表を取得したければtableを、箇条書きになっているものを取得したければlistを選択します。
ただ、この関数はその取得したい情報がHTML内で<table>タグまたは<li>タグで囲まれていなかったら使えないので注意です。
関数で取得できないデータもあります
今回紹介した関数で取得できないデータもございます。また、大量のデータの取得には向かないため、もし、ヤフオクやAmazonの出品情報などを収集したい方がいらっしゃいましたらココナラで受け付けしていますので、お気軽にご相談ください。


コメント